Home SaltStack-Formulas Project Introduction
Working with Metadata¶
Every IT solution can be described by using several layers of objects, where the objects of higher layer are combinations of the objects from lower layers. For example, we may install ‘apache server’ and call it ‘apache service’, but there are objects that contain multiple services like ‘apache service’, ‘mysql service’, and some python scripts (for example keystone), we will call these “keystone system” or “freeipa system” and separate them on a higher (System) layer. The systems represent units of business logic and form working components. We can map systems to individual deployments, where “openstack cluster” consists of “nova system”, “neutron system” and others OpenStack systems and “kubernetes cluster” consists of “etcd system” , “calico system” and few others. We can define and map PaaS, IaaS or SaaS solutions of any size and complexity.

Decomposition of services, systems and clusters
This model has been developed to cope with huge scopes of services, consisting of hundreds of services running VMs and containers across multiple physical servers or locations. Following text takes apart individual layers and explains them in further detail.
Scaling Metadata Models¶
Keeping consistency across multiple models/deployments has proven to be the most difficult part of keeping things running smooth over time with evolving configuration management. You have multiple strategies on how to manage your metadata for different scales.
The service level metadata can be handled in common namespace not by formulas itself, but it is recommended to keep the relevant metadata states
Separate Cluster with Single System Level¶
With introduction of new features and services shared deployments does not provide necessary flexibility to cope with the change. Having service metadata provided along formulas helps to deliver the up-to-date models to the deployments, but does not reflect changes on the system level. Also the need of multiple parallel deployments lead to adjusting the structure of metadata with new common system level and only cluster level for individual deployment(s). The cluster layer only contains soft parametrization and class references.
Separate Cluster with Multiple System Levels¶
When customer is reusing the provided system, but also has formulas and system on its own. Customer is free to create its own system level classes.
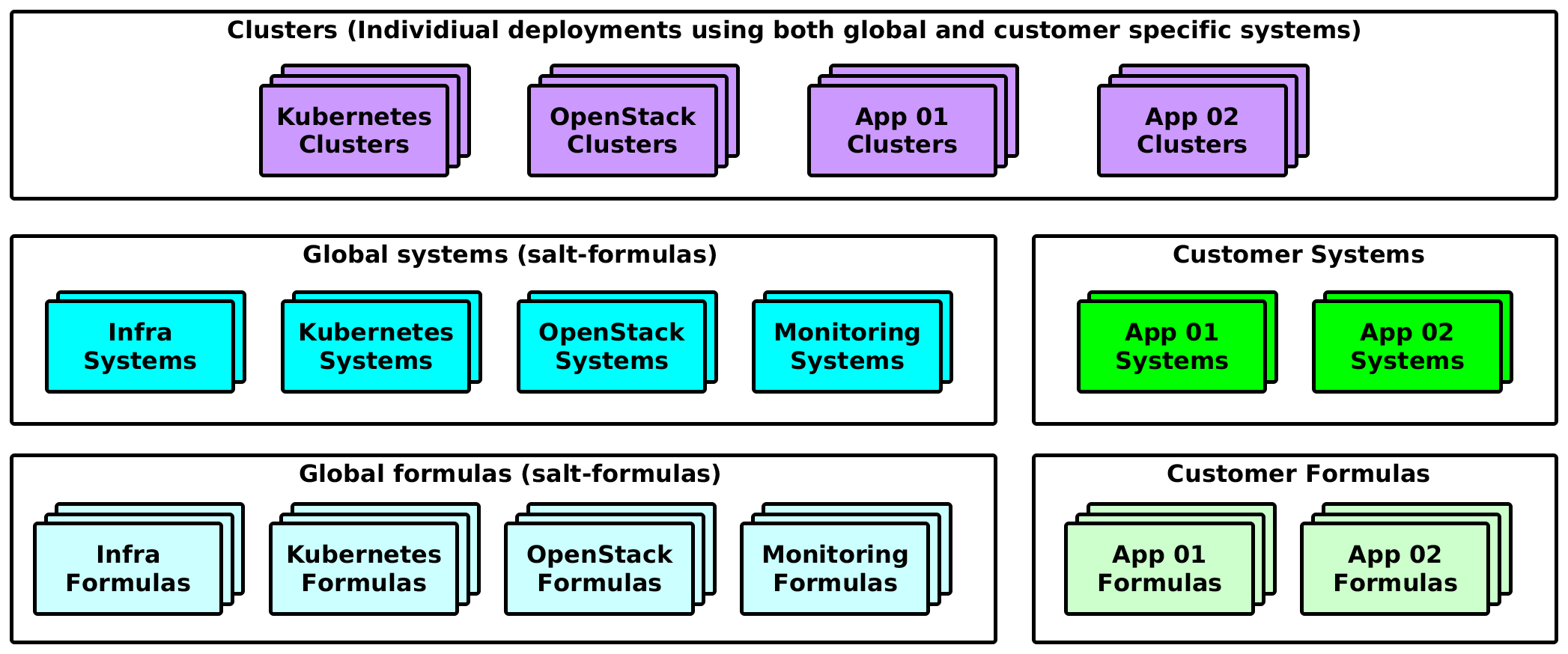
Multiple system levels for customer services’ based payloads
In this setup a customer is free to reuse the generic formulas with generic systems. At the same time he’s free to create formulas of it’s own as well as custom systems.
Handling Sensitive Metadata¶
Sensitive data refers to any information that you would not wish to share with anyone accessing a server. This could include data such as passwords, keys, or other information. For sensitive data we use the GPG renderer on salt master to cipher all sensitive data.
To generate a cipher from a secret use following command:
$ echo -n "supersecret" | gpg --homedir --armor --encrypt -r <KEY-name>
The ciphered secret is stored in block of text within PGP MESSAGE
delimiters, which are part of cipher.
-----BEGIN PGP MESSAGE-----
Version: GnuPG v1
-----END PGP MESSAGE-----
Following example shows full use of generated cipher for virtually any secret.
parameters:
_param:
rabbitmq_secret_key: |
-----BEGIN PGP MESSAGE-----
Version: GnuPG v1
hQEMAweRHKaPCfNeAQf9GLTN16hCfXAbPwU6BbBK0unOc7i9/etGuVc5CyU9Q6um
QuetdvQVLFO/HkrC4lgeNQdM6D9E8PKonMlgJPyUvC8ggxhj0/IPFEKmrsnv2k6+
cnEfmVexS7o/U1VOVjoyUeliMCJlAz/30RXaME49Cpi6No2+vKD8a4q4nZN1UZcG
RhkhC0S22zNxOXQ38TBkmtJcqxnqT6YWKTUsjVubW3bVC+u2HGqJHu79wmwuN8tz
m4wBkfCAd8Eyo2jEnWQcM4TcXiF01XPL4z4g1/9AAxh+Q4d8RIRP4fbw7ct4nCJv
Gr9v2DTF7HNigIMl4ivMIn9fp+EZurJNiQskLgNbktJGAeEKYkqX5iCuB1b693hJ
FKlwHiJt5yA8X2dDtfk8/Ph1Jx2TwGS+lGjlZaNqp3R1xuAZzXzZMLyZDe5+i3RJ
skqmFTbOiA==
=Eqsm
-----END PGP MESSAGE-----
rabbitmq:
server:
secret_key: ${_param:rabbitmq_secret_key}
...
As you can see the GPG encrypted parameters can be further referenced with
reclass interpolation ${_param:rabbitmq_secret_key} statement.
Creating new Models¶
Following text shows steps that need to be undertaken to implement new functionality, new system or entire deployment:
Creating a New Formula (Service Level)¶
If some of required services are missing, you can create a new service formula for Salt with the default model that describe the basic setup of the service. The process of creating new formula is streamlined by Using Cookiecutter and after the formula is created you can check Formula Authoring Guidelines chapter for furher instructions.
If you download formula to salt master, you can point the formula metadata to the proper service level directory:
ln -s <service_name>/metadata/service /srv/salt/reclass/classes/service/<service_name>
And symlink of the formula content to the specific salt-master file root:
ln -s <service_name>/<service_name> /srv/salt/env/<env_name>/<service_name>
Creating New Business Units (System Level)¶
If some ‘system’ is missing, then you can create a new ‘system’ from the set of ‘services’ and extend the ‘services’ models with necessary settings for the system (additional ports for haproxy, additional network interfaces for linux, etc). Do not introduce too much of hard metadata on the system level, try to use class references as much as possible.
Creating New Deployments (Cluster Level)¶
Determine which products are being used in the selected deployemnt, you can have infrastructure services, applications, monitoring products defined at once for single deployemnt. You need to make suere that all necessary systems was already created and included into global system level, then it can be just referenced. Follow the guidelines further up in this text.
Making Changes to Existing Models¶
When you have decided to add or modify some options in the existing models, the right place of the modification should be considered depending of the impact of the change:
Updating Existing Formula (Service Level)¶
Change the model in salt-formula-<service-name> for some service-specific improvements. For example: if the change is related to the change in the new package version of this service; the change is fixing some bug or improve performance or security of the service and should be applied for every cluster. In most cases we introduce new resources or configuration parameters.
Example where the common changes can be applied to the service: https://github.com/openstack/salt-formula-horizon/tree/ master/metadata/service/server/
Updating Business Unit (System Level)¶
Change the system level for a specific application, if the base services don’t provide required configurations for the application functionality. Example where the application-related change can be applied to the service,
Updating Deployment Configurations (Cluster Level)¶
Changes on the cluster level are related to the requirements that are specific for this particular cluster solution, for example: number and names of nodes; domain name; IP addresses; network interface names and configurations; locations of the specific ‘systems’ on the specific nodes; and other things that are used by formulas for services.