Home SaltStack-Formulas Project Introduction
ReClass - Recursive Classification¶
reclass in node centric classifier for any configuration management. When reclass parses a node or class definition and encounters a parent class, it recurses to this parent class first before reading any data of the node (or class). When reclass returns from the recursive, depth first walk, it then merges all information of the current node (or class) into the information it obtained during the recursion.
This means any class may define a list of classes it derives metadata from, in which case classes defined further down the list will be able to override classes further up the list.
Core Functions¶
reclass is very simple and there are only two main concepts.
Deep Data Merging¶
When retrieving information about a node, reclass first obtains the node definition from the storage backend. Then, it iterates the list of classes defined for the node and recursively asks the storage backend for each class definition. Next, reclass recursively descends each class, looking at the classes it defines, and so on, until a leaf node is reached, i.e. a class that references no other classes.
Now, the merging starts. At every step, the list of applications and the set of parameters at each level is merged into what has been accumulated so far.
Merging of parameters is done “deeply”, meaning that lists and dictionaries are extended (recursively), rather than replaced. However, a scalar value does overwrite a dictionary or list value. While the scalar could be appended to an existing list, there is no sane default assumption in the context of a dictionary, so this behaviour seems the most logical. Plus, it allows for a dictionary to be erased by overwriting it with the null value.
After all classes (and the classes they reference) have been visited, reclass finally merges the applications list and parameters defined for the node into what has been accumulated during the processing of the classes, and returns the final result.
Parameter Interpolation¶
Parameters may reference each other, including deep references, e.g.:
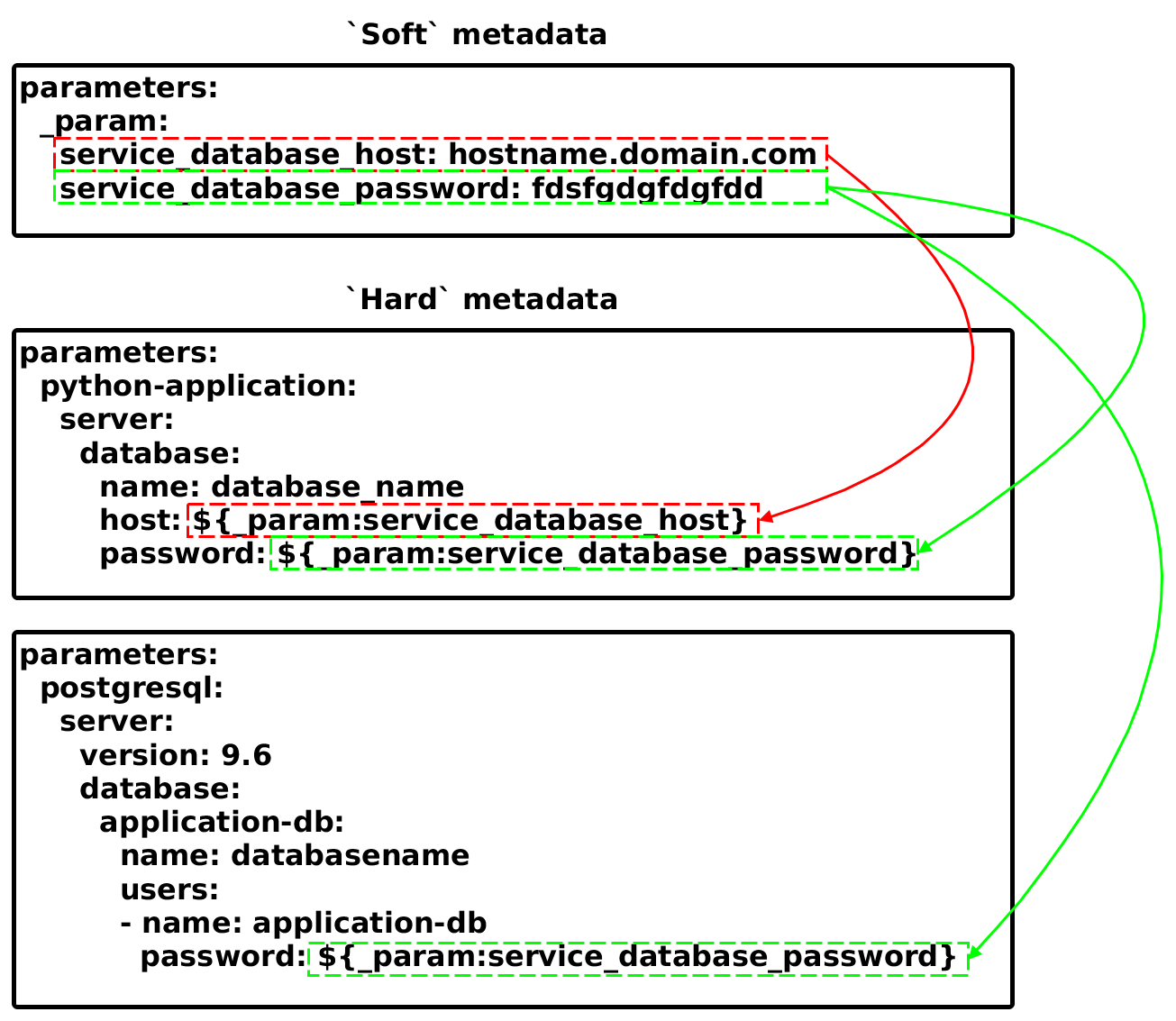
Parameter interpolation of soft parameters to hard metadata models
After merging and interpolation, which happens automatically inside the storage modules, the python-application:server:database:host parameter will have a value of “hostname.domain.com”.
Types are preserved if the value contains nothing but a reference. Hence, the value of dict_reference will actually be a dictionary.
Overriding the Metadata¶
The reclass deals with complex data structures we call ‘hard’ metadata, these are defined in class files mentioned in previous text. These are rather complex structures that you don’t usually need to manage directly, but a special dictionary for so called ‘soft’ metadata was introduced, that holds simple list of most frequently changed properties of the ‘hard’ metadata model. It uses the parameter interpolation function of reclass to achieve defining parameter at single location.
The ‘Soft’ Metadata¶
In reclass storage is a special dictionary called _param, which contains keys that are interpolated to the ‘hard’ metadata models. These soft parameters can be defaulted at system level or on cluster level and or changed at the node definition. With some modufications to formulas it will be also possible to have ETCD key-value store to replace or ammed the _params dictionary.
parameters:
_param:
service_database_host: hostname.domain.com
All of these values are preferably scalar and can be referenced as
${_param:service_database_host} parameter. These metadata are considered
cluster level readable and can be overriden by reclass.set_cluster_param
name value module.
The ‘Hard’ Metadata¶
This metadata are the complex metadata structures that can contain interpolation stings pointing to the ‘soft’ metadata or containing precise values.
parameters:
python-application:
server:
database:
name: database_name
host: ${_param:service_database_host}